顶功编码
上一节中您通过学习冰雪四拼的拼写规则来缩短了带调拼音的拼写长度。不过,这样每个字仍然需要三四键,而且输入结束后需要空格上屏。更重要的是,整句拼音输入的形式不利于精准把控输入的内容,因为在整句中间出现音字转换错误的时候,通常很难修改;另一方面,输入平台一般只会机械地记录用户输入的每一句话,而用户不太可能再次输入完全相同的一句话,因此输入平台并没有很高效地学习用户的输入习惯。
综合考虑以上几点,会发现「每次输入需要空格上屏」这个特性实际上让整句的问题变得更严重了,因为用户为了尽可能减少空格会倾向于输入更长的一句话,但这不利于精准性和智能学习。有没有办法既能按比较短的单位来输入,又不需要空格上屏呢?有的!这就是顶功的编码方式。
对于冰雪四拼来说,这意味着一个词的编码不再是每个音节的编码连起来打,而是应用了一套新的构词规则。初学者对于这套规则可能会感觉到颠三倒四,但是熟悉之后就会感觉到无比自然。
构词规则
本方案使用统一的规则来编码所有不同长度的词:
先打各个音节的声母编码;如果首选未命中,追加末音节的编码直至三码;如果首选仍未命中,追加首音节的编码直至三码。
也就是说,虽然冰雪四拼每个音节的拼写可能是三或四码,但是构词的时候词的首音节和末音节最多用前三码,而其他音节最多用第一码。各个音节的声母是首先必须要打的,后面追加的编码称为「补码」,可能有 0 ~ 4 个。到底需要打多少个补码,取决于词的频率,常用的词打得少,不常用的词就打得多。以下针对不同长度的词分别举几个例子:
- 单音节词:「有」的编码为
f,「又」的编码为fo,「由」的编码为fou; - 双音节词:「你好」的编码为
nh,「希望」的编码为xsi,「手机」的编码为vjii,「冰雪」的编码为bxoui,「元气」的编码为kqiaoo; - 三音节词:「为什么」的编码为
svm,「变压器」的编码为bfqi,「最低点」的编码为zdduo; - 四音节词:「感同身受」的编码为
gtvv,「将计就计」的编码为jjjji,「附庸风雅」的编码为ffffuu; - 以此类推,
音节词的编码可能为 码到 码不等。
对于大于等于五个音节的词语,进一步规定第五个声母以及之后的所有声母需要用大写字母来输入。例如「科学发展观」的编码为 kxfwG,「哀莫大于心死」的编码为 rmdkXS,「中华人民共和国」的编码为 whrmGHG。另外,由于动态调频的存在,实际输入的编码可能与上述介绍有细微的差异。
为什么要这样设置构词规则?答案是——为了顶功!
观察上面的规则,容易发现规律如下:每个词的编码都是先有几个 bpmfdtnlgkhjqxzcsrwyv 这样的辅音字母,然后可能有几个 aeiou 这样的元音字母(当然也可能没有元音字母)。这意味着,如果用户输入完元音字母之后再输入辅音字母,就说明一定已经开始输入下一个词了,此时输入平台做出判断将前一个词顶上屏幕。在分词输入的前提下,这无疑节省了大量的空格键。
注意,对于「有 f」、「你好 nh」、「为什么 svm」这样的只包含辅音字母的编码来说,因为不知道后面还有没有更多的辅音字母,所以仍然需要使用空格上屏。但是,对于四音节词以及更长的词来说,后面的辅音字母是用大写输入,因此即使是「感同身受 gtvv」这样的也可以在输入下一个词的首码的时候自动被顶上屏。
动态码长
上面提到,在输入完声母之后,后面的补码可能有 0 ~ 4 个。在输入的过程中,建议的打法是:观察候选中的第一个词,然后不断追加补码使得想要的词出现在首选;如果输完四个之后仍然没有出现在首选,则继续用数字键和翻页键选择候选(这种情况极少)。
用户不断输入的过程中,输入平台会记录用户输入各个词的频率,然后根据一定的算法来调整词在候选中的位置。结果就是,用户常用的词所使用的补码就比较少甚至没有;不常用的词就需要输入更多补码。这个特性称为动态码长。
自动造词
本方案词库中含有 180 万来自多个渠道的词汇,但是用户在自己的使用中仍然会遇到需要的词词库中没有的情况。这时就需要造词。
选择法
本方案的造词方式与一般的拼音输入法完全相同,用户应该会感到很熟悉。输入词的编码时,候选中会首先显示与输入编码音节数量相等的候选词,然后排在后面的是较短的候选词。此时可以直接通过数字键来选择短词,从而把长词拆解成短词并依次确认,最终上屏;上屏后,用户词典中就会出现这些短词连接起来所对应的长词。例如,下面两张图展示了造词「四拼」的过程:当输入到 spioi 五码时,发现候选中只有三个二字词且不包含「四拼」,说明「四拼」不存在于词库中,此时直接选择「四」然后再选择「拼」即完成了造词。


定位法
不过,如果想要的短词不在第一页,那翻页寻找就比较麻烦了。因此,本方案还提供了另一种方式来快速完成长词的拆解,那就是定位补码的方式。定位的快捷键是:1, 4, 5, 6 和 7。其中,1, 4, 5, 6 会分别把光标移到第一个、第二个、第三个或者第四个音节处,而 7 则会返回最后一个音节的末尾。完成定位之后,可以追加补码来筛选字词,然后确认这一片段对应的字词;对各个片段依次定位并确认之后,即完成造词。下面我们举几个例子:
- 想打「谱方法」这个三字词,输入到
pffau时可以确定词库里没有这个词,此时直接按 1 定位到第一个音节后面,输入uu补全「谱」的音节码,确认「谱」之后再确认「方法」,即完成造词:


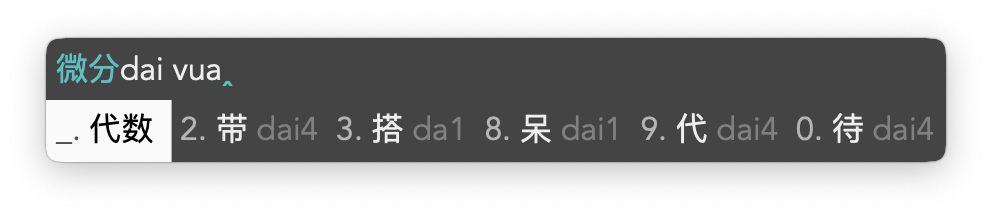
- 想打「微分代数」这个四字词,输入到
sfdvua时可以确定词库里没有这个词,此时直接按 4 定位到第二个音节后面,补码确认「微分」之后再补码确认「代数」,即完成造词:
- 想打「态叠加原理」这个五字词,输入到
tdjkL时可以确定词库里没有这个词,此时直接按 5 定位到第三个音节后面,补码确认「态叠加」之后再补码确认「原理」,即完成造词:

以此类推,掌握这几个快捷键之后,就可以对几乎所有可能的组词方式(1+1, 1+2, 2+1, 1+1+1, 2+2, 2+3, 3+2, ...)快速地拆解完成造词。
概率法
若词库里没有任何词可以匹配用户输入的编码,则输入引擎会用组句功能来用短词自动生成一个与用户输入的音节数量相同长度的词。由于这个功能的存在,使得本方案常常能出现以下奇特的效果:明明词库里没有用户想打的词,但输入引擎准确「猜」出来了用户想要打的词,此时本方案类似于一个整句输入方案。例如,想输入「密度矩阵」,输入到 mdjweoia 时词库里没有任何词能匹配这个编码,但是词库里有「密度」和「矩阵」且两者频率都不低,因此通过组合的方式正好「猜」出来了用户想要的词「密度矩阵」。

概率法对于 2+2 形式的四字词成功率尤其高,这是因为用户尝试打这个复合词之前通常已经打过了相应的二字词,因此在用户词典里两个二字词的频率较高,所以四字词组合出来多半是这个结果。由于汉语的特点,大多数专业术语都以 2+2 的四字复合词的形式出现,因此使用本方案输入专业文本时体验是极好的。
用户应掌握上述三种造词的方式以及使用场景,通过逐步的使用来融会贯通,这样才能最大程度发挥本方案的造词功能。对于后两种方式,到底是发现候选中没有想要的词就去定位编码,还是多打几码尝试让组句功能组出想要的词,存在一定的权衡,用户需要找到最适合自己的方式并养成自己的习惯。推荐的用法是:四字或更长的复合词可以把编码打全让概率法碰碰运气,而其他情况及时定位会来得更快。
学习完构词规则、动态码长和自动造词的特性后,下面再介绍几个进一步引入的优化特性,以更好地服务于顶功输入:
优化特性 1:首选后置
在逐码输入的过程中,如果一个字词已经在首选出现过,那么在后续输入中它将不再位于首选,这可以充分利用编码空间,并且降低重码。
优化特性 2:固定候选
一般情况下,输入各种编码时候选的排序会随着用户的使用逐渐调整,以贴合用户的使用习惯。但是,如果高频词的排序常常变动,则难以熟练掌握。因此,本方案精心设计了一些固定候选词,这些词在输入对应编码时总是处于首位,可以直接顶屏或者(在不能顶屏的情况下)用空格上屏,并且这些都定义在 snow_sipin.fixed.txt 中,可以自由修改。
相比于声笔简整和声笔拼音,本方案设计的固定候选词更多,包括了 636 个单音节词和 510 个双音节词,而且进行了更加细致的优化。这使得在一般的连续性输入文本中固定候选词的总频率已经达到了 70% 以上,所以掌握固定候选词可以快速提高输入方案的熟练度。这些固定候选词的规律是:
- 单音节词的一码(21 个)、二码(105 个)和三码(510 个)全部固顶;
- 双音节词的二码(441 个)全部固顶,而三码和四码选取了一部分(69 个)固顶;
为了减小固定候选词的记忆难度,本方案选取固定候选词的时候采取了语义优先的策略,也就是语义相关的词往往具有相同或相关的固顶码长,记住一个往往就记住了一大片。例如,
...
# 事物代词
wg 这个
ng 那个
nge 哪个
wr 这儿
nr 那儿
nri 哪儿
wl 这里
nl 那里
nli 哪里
...在 snow_sipin.fixed.txt 中有很多像这样的语义集中的「区块」,看过一次之后就能留下比较深刻的印象。
另外,「的」和「了」两个字因为频率非常高,所以分别采用 ; 和 / 键输入,不占用常规固定候选词的位置。如果不喜欢这个设定,可以在固定候选词文件中自定义。作为替代,分号用 | 输入(即 Shift + \),顿号用 \ 输入。
优化特性 3:无理音节(可选)
在设置固定候选词的时候,注意到「三」和「四」的声母都是 s,无法在「三个」、「四个」等词中保持同样的码长,而且因为「五」的声母「零合」也在 s 上,让这个问题更加严重了。另外,「日」和「二」的前三码都是 ria,也破坏了一些词的整齐性。
为了解决这个问题,对「三」、「五」、「日」这三个字所在的音节增加了无理音节码:
san1这个音节也可以用heu打出来,同时也是「三」的固顶码wu3这个音节也可以用gue打出来,同时也是「五」的固顶码ri4这个音节也可以用rii打出来,同时也是「日」的固顶码
记忆的时候,可以把它们当成是一周中的三天,用「周三 wheu」「周五 wgue」「周日 wrii」这三个固定候选词来辅助记忆。另外,虽然这些音节的其他字也能用无理码打出来,但是并不推荐这样做,因为会干扰常规音节码的键位;如果反过来当成是改变了这三个字的读音,会更容易适应。
如果您记住了这些无理音节,并想强制自己使用,可以在补丁文件(snow_sipin.custom.yaml)里写入:
patch:
speller/force_special: true这样的好处是不仅固顶词不会冲突,其他动态调频的常规词也不会再冲突了。例如,您正在输入「二零二四」和「二零二五」两个词,若仅仅启用无理音节码而不强制使用,则虽然 rlrg 可以唯一地得到「二零二五」这个词,但是 rlrs 仍然会同时出现「二零二四」和「二零二五」的候选。而若强制使用无理音节码,则可以完全分离这两个词:

